Working with Data
Writ lets users combine datasets and text into a single document. Datasets are the building block upon which visualizations such as charts, graphs, and tables are created. Datasets can come from from query results from data warehouses (plus many other online data stores) or from manually uploaded data such as CSV's and Excel files. Most users choose to make use SQL-derived data sources to allow for future automation.
Setting Up a Connection
Writ connects to most online data sources, including data warehouses, SaaS tools, and beyond. You can also upload a CSV or Excel file if you're not ready to hook up a data source. Currently, Writ supports the following connection types:
- Databricks
- Snowflake
- Microsoft SQL
- Redshift
- Athena
- Postgres
- Salesforce
- ServiceNow
If you have a connection type you'd like to see added, just let us know and we'll get it added in 24-48 hours.
Creating your first Dataset
Online Data Sources (SQL)
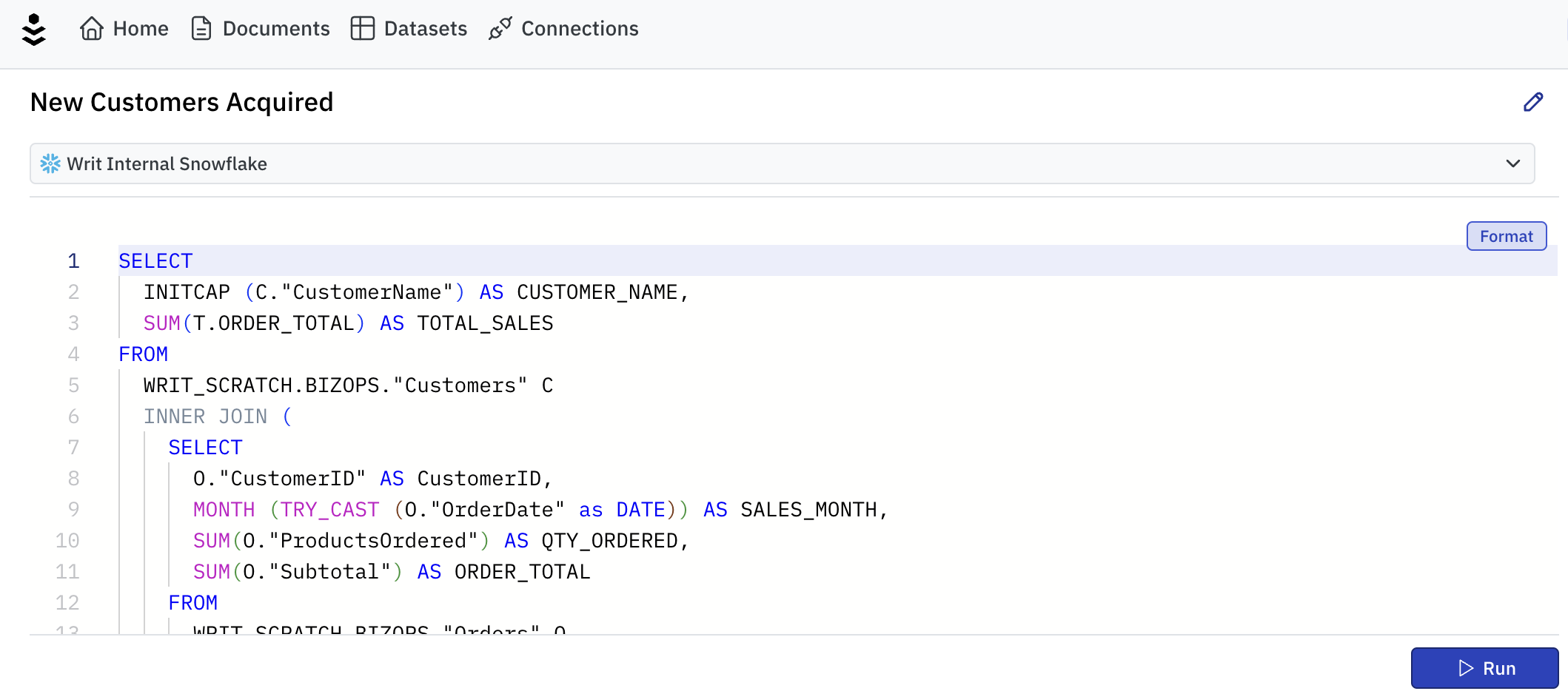
Once you've established a connection, creating a dataset is as easy as querying one or more tables with SQL. For example, if you had a table called '''FOO''', you could write SELECT * FROM FOO, depending on the SQL dialect. See below for a sample Snowflake query:
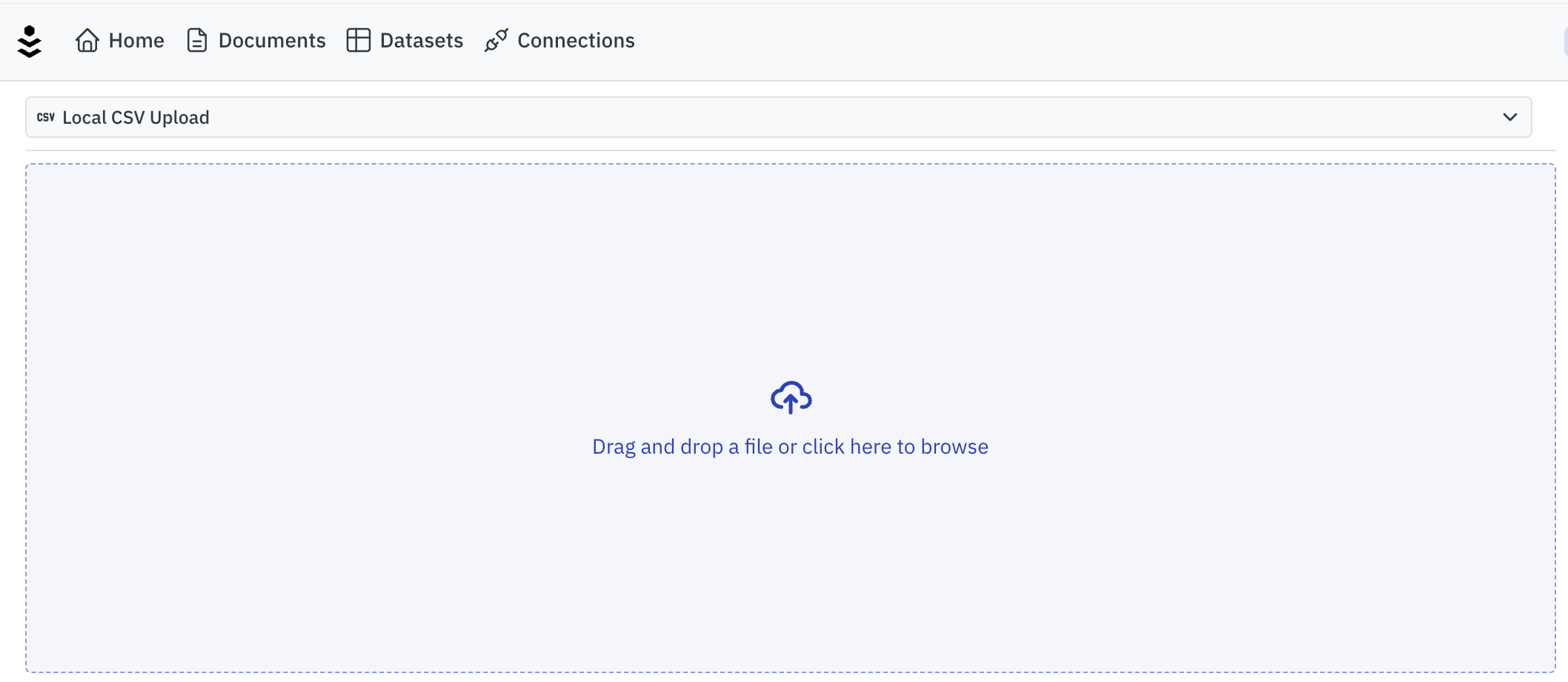
Uploaded Datasets
Alternatively, users can simply upload a CSV or Excel file through the connections menu.
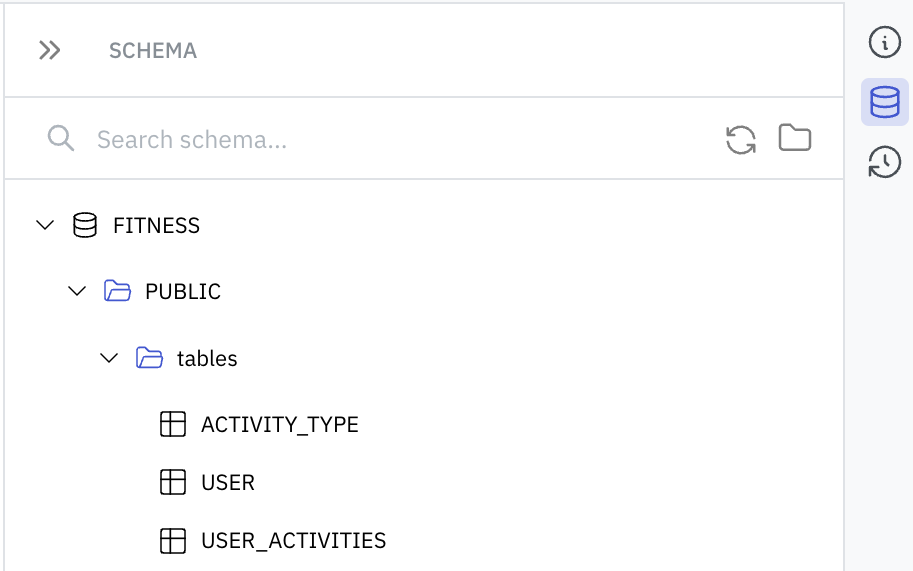
Browsing Schema
Writ has an integrated Schema browser that retrieves both database and table listings as well as column/data types. This helps populate the type-ahead query editor. To explore, simply click the schema tab. Note that you can also Refresh the schema at anytime.
Dataset History
Unique to Writ, we cache and encrypt all historical uploads of datasets, both for flat files (CSV's, Excel) and SQL results. This serves a few key purposes:
- Allows teammates to more easily collaborate on the same data without needing to create duplicate content
- Helps customers reduce their consumption-based database bills. Instead of paying your data warehouse vendor, let us cache things super efficiently.
- Supports Document History when looking back at historical versions and wanting to see the data from the time the document was originally published.
Datasets do not need to maintain a consistent schema throughout history, but mindful of changing tables if you choose to take advantage of this.
If at any time you wish to wish to see the historical versions of a dataset, simply click the Dataset History tab in the editor.
Dataset Sharing
Datasets are automatically shared with users that are granted access to a document that contains data. For example, if a document has one or more datasets, any user with permission to that document will receive View access to the embedded datasets.
Datasets can also be explicitly shared with users.